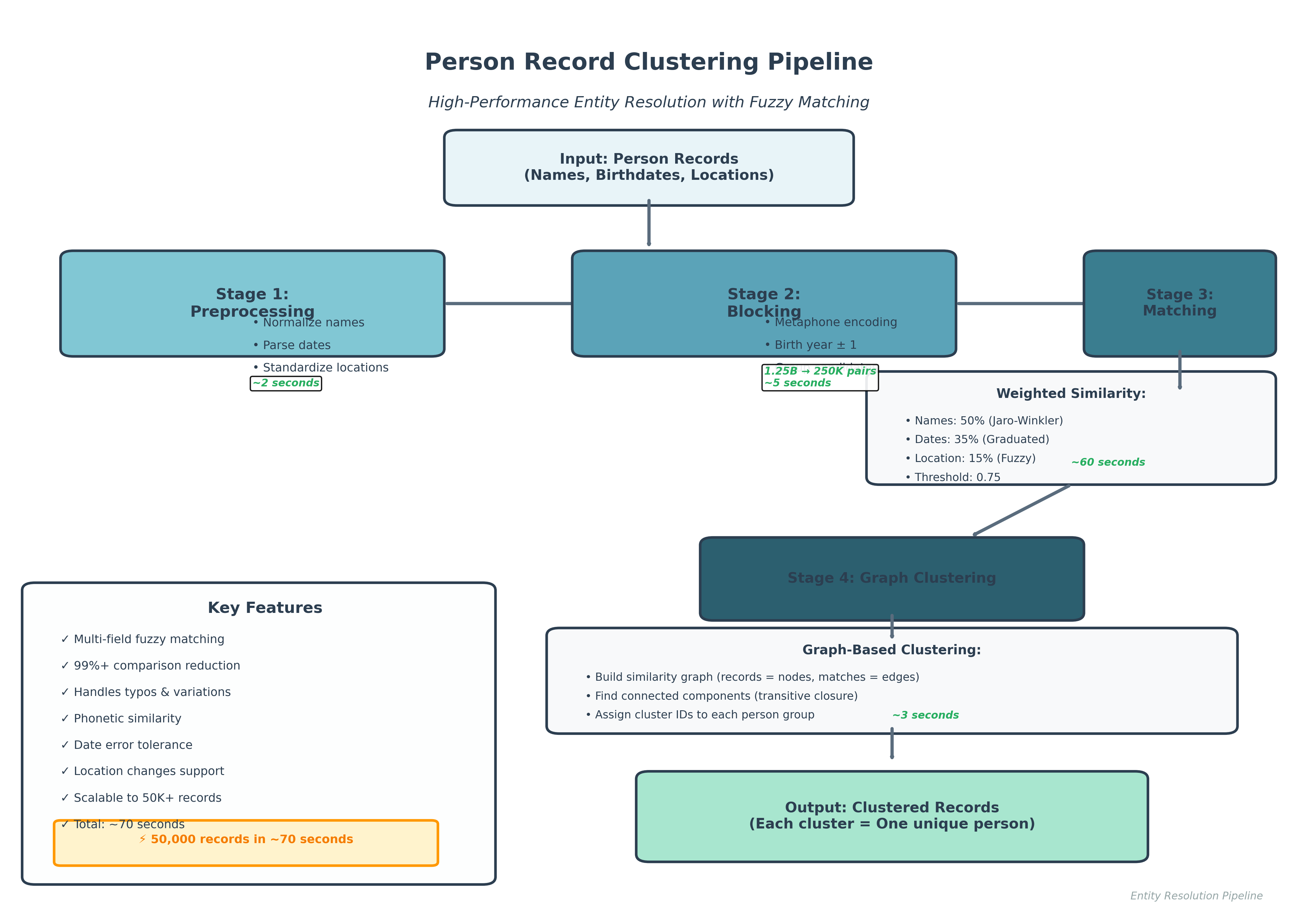
Overview
An entity resolution system that identifies and clusters duplicate person records across large datasets. Handles real-world data variations including typos, date errors, and location changes.
Technical Stack
- Fuzzy Matching: Metaphone encoding, Jaro-Winkler distance, Token Sort Ratio
- Graph Algorithms: Connected components for transitive clustering
- Data Processing: Pandas, NumPy
- Python: Core implementation
Pipeline Steps
1. Preprocessing
- Normalize names and standardize locations
- Parse dates with multiple format support
2. Blocking Strategy
- Group candidates by phonetic encoding + birth year (±1)
- Reduces comparisons from O(n²) to O(n)
3. Fuzzy Matching
- Name similarity (50% weight): Token Sort Ratio + Jaro-Winkler
- Date similarity (35% weight): Graduated scoring
- Location similarity (15% weight): Fuzzy string matching
- Threshold: 0.75 for match classification
4. Graph Clustering
- Build similarity graph from matched pairs
- Find connected components for transitive closure
Performance
On 50,000 records:
- Total runtime: ~70 seconds
- Blocking reduces comparisons by 99%+ (1.25B → 250K pairs)